Es 基本概念
集群(cluster)
由一个名称标识( elisticsearch.yml 中 cluster.name: “docker-cluster” ),由一个或多个节点(node)组成。
# 查看集群状态
GET _cluster/state节点 (node)
默认情况下,群集中的每个节点都可以处理 HTTP 和 Transport 流量。 Transport 层专门用于节点之间的通信。 HTTP 层由 REST 客户端使用。
所有节点都知道集群中的所有其他节点,并且可以将客户端请求转发到适当的节点。
根据作用分类:
- master-eligible node:主节点,管理集群,去中心化,避免单点故障,自动选举
- data node : 数据节点,保存和操作数据,如CRUD、搜索和聚合
- ingest node :数据接入节点。 角色为 ingest。
- remote-eligible node :远程合格节点。角色为 remote_cluster_client ,可以充当远程客户端。
- Machine learning node : 机器学习节点。
- transform node :转换节点。
Coordnating node 协调节点
搜索请求或批量索引请求等请求可能涉及保存在不同数据节点上的数据。 例如,搜索请求在两个阶段中执行,这两个阶段由接收客户请求的节点(即协调节点)协调。
在分散阶段,协调节点将请求转发到保存数据的数据节点。 每个数据节点在本地执行该请求,并将其结果返回到协调节点。 在收集阶段,协调节点将每个数据节点的结果缩减为单个全局结果集。
每个节点都隐式地是一个协调节点。 这意味着通过 node.roles 具有明确的空角色列表的节点将仅充当协调节点,无法禁用。 结果,这样的节点需要具有足够的内存和 CPU 才能处理收集阶段。协调节点的定义为: node.roles: []
角色:
- master
- data
- data_content
- data_hot
- data_warm
- data_cold
- data_frozen
- ingest
- ml
- remote_cluster_client
- transform
索引(index)
对应关系型数据库里的 databse 概念(但不完全相同)。一个集群,可以有多个索引。是一个逻辑名称。
索引是文档(对应关系数据库的 record )的集合。
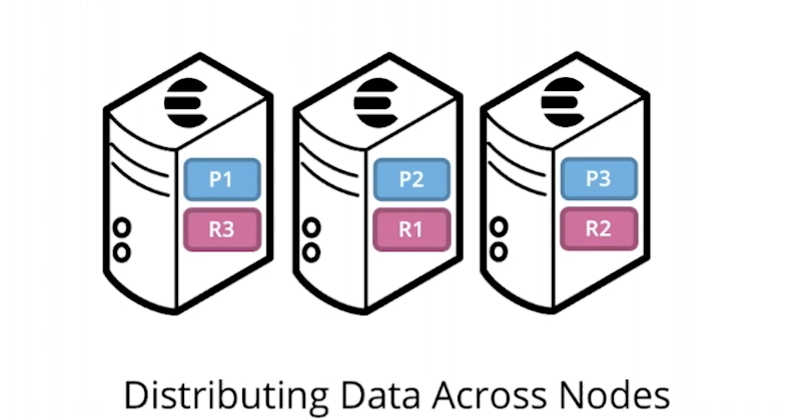
分片 (shard)
分布式的搜索引擎,索引通常被拆分为多份,这份就叫分片(shard),分布在多个节点上。es 自动管理和平衡这些分片。
因此一个索引可以存储,超过单节点硬件限制的数据。
优点:
- 方便水平拓展
- 多节点并行操作(潜在地),提高吞吐
分片的类型:
primary shard :每个文档都有一个 primary shard 。 索引文档时,它首先在 Primary shard 上编制索引,然后在此分片的所有副本上(replica)编制索引。索引可以包含一个或多个主分片。 此数字确定索引相对于索引数据大小的可伸缩性。 创建索引后,无法更改索引中的主分片数。
replica shard:每个主分片可以具有零个或多个副本分片。数量可以动态修改(默认1个)。有两个目的:
1.增加故障转移:如果主要故障,可以将副本分片提升为主分片。即使你失去了一个 node,那么副本分片还是拥有所有的数据。
2.提高性能:get 和 search 请求可以由主 shard 或副本 shard 处理。
主分片 和 副本分片 的区别:只有主分片可以接受索引请求。副本分片和主分片都可以提供查询请求。
shard 健康状态
- 红色:集群中至少有一个主分片未分配
- 黄色:已分配所有主分片,但至少一个副分片未分配
- 绿色:分配所有分片
文档 (document)
es 索引或搜索的最小数据单元是文档,对应关系数据库的 record。
特点:
- 独立
- 可以嵌套的
- schemaless 不需要预先定义模式,可以动态调整
文档通常是数据的 JSON 表示形式。JSON over HTTP 是与 Elasticsearch 进行通信的最广泛使用的方式。
相互关系
每个 Index 由一个或许多的 documents 组成,并且这些 documents 可以分布于不同的 shard 之中,一个 node 里可以放零个或多个 shard (取决与 node 的种类),一个或多个节点(node)组成集群。
如:一个 index 有5个 shard 及1个 replica
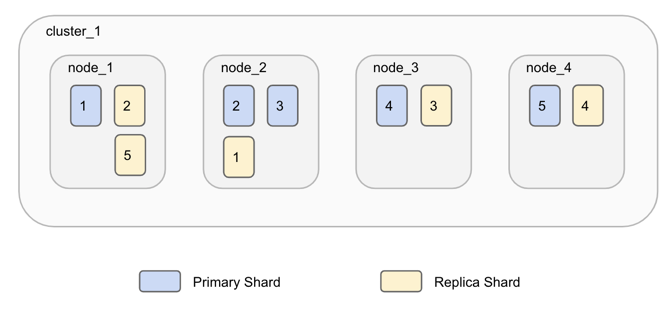
这些 shard 分布于不同的物理机器上